

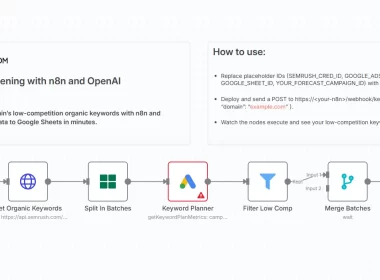

Polars is a blazing-fast DataFrame library, often seen as a modern alternative to Pandas for performance-critical tasks. It’s written in Rust and uses Apache Arrow for efficient memory management.
Polars Basics
Polars is a high-performance DataFrame library for Rust and Python. It’s designed for speed and memory efficiency, often outperforming Pandas on large datasets.
import polars as pl
import numpy as np # Still useful for numeric operations
# Creating a Series (Polars calls them Series)
s = pl.Series([1, 2, 3, 4, 5])
print(s)
# > shape: (5,)
# > Series: '' [i64]
# > [
# > 1
# > 2
# > 3
# > 4
# > 5
# > ]
s_labeled = pl.Series("my_series", [10, 20, 30]) # Series can have a name
print(s_labeled)
# > shape: (3,)
# > Series: 'my_series' [i64]
# > [
# > 10
# > 20
# > 30
# > ]
# Creating a DataFrame from a dictionary
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [25, 30, 35, 40],
'City': ['New York', 'London', 'Paris', 'New York']
}
df = pl.DataFrame(data)
print(df)
# > shape: (4, 3)
# > ┌─────────┬─────┬──────────┐
# > │ Name ┆ Age ┆ City │
# > ╞═════════╪═════╪══════════╡
# > │ Alice ┆ 25 ┆ New York │
# > │ Bob ┆ 30 ┆ London │
# > │ Charlie ┆ 35 ┆ Paris │
# > │ David ┆ 40 ┆ New York │
# > └─────────┴─────┴──────────┘
# Creating a DataFrame from a list of lists (with schema)
data_list = [['John', 28, 'Berlin'], ['Anna', 22, 'Rome']]
df_list = pl.DataFrame(
data_list,
schema=['Name', 'Age', 'City'] # Explicit schema is good practice
)
print(df_list)
# > shape: (2, 3)
# > ┌──────┬─────┬────────┐
# > │ Name ┆ Age ┆ City │
# > ╞══════╪═════╪════════╡
# > │ John ┆ 28 ┆ Berlin │
# > │ Anna ┆ 22 ┆ Rome │
# > └──────┴─────┴────────┘
# Basic DataFrame Info
print(df.head(2)) # Displays first N rows > First 2 rows of df
print(df.tail(1)) # Displays last N rows > Last row of df
print(df.estimated_size("mb")) # Estimated memory usage in MB > (e.g., 0.000109968)
print(df.columns) # Returns column names as a list > ['Name', 'Age', 'City']
print(df.schema) # Returns column names and their data types > {'Name': Utf8, 'Age': Int64, 'City': Utf8}
Data Selection and Filtering
Accessing specific columns or rows in a Polars DataFrame. Polars emphasizes expression-based operations.
# Select a single column (returns a Series)
print(df['Name'])
# > shape: (4,)
# > Series: 'Name' [str]
# > [
# > "Alice"
# > "Bob"
# > "Charlie"
# > "David"
# > ]
# Select multiple columns (returns a DataFrame)
print(df.select(['Name', 'Age'])) # Recommended way for multiple columns
# > shape: (4, 2)
# > ┌─────────┬─────┐
# > │ Name ┆ Age │
# > ╞═════════╪═════╡
# > │ Alice ┆ 25 │
# > │ Bob ┆ 30 │
# > │ Charlie ┆ 35 │
# > │ David ┆ 40 │
# > └─────────┴─────┘
# Select rows by index (use slice for ranges)
print(df[0]) # Selects the first row as a DataFrame
# > shape: (1, 3)
# > ┌───────┬─────┬──────────┐
# > │ Name ┆ Age ┆ City │
# > ╞═══════╪═════╪══════════╡
# > │ Alice ┆ 25 ┆ New York │
# > └───────┴─────┴──────────┘
print(df[1:3]) # Rows from index 1 up to (but not including) 3
# > shape: (2, 3)
# > ┌─────────┬─────┬────────┐
# > │ Name ┆ Age ┆ City │
# > ╞═════════╪═════╪════════╡
# > │ Bob ┆ 30 ┆ London │
# > │ Charlie ┆ 35 ┆ Paris │
# > └─────────┴─────┴────────┘
# Filtering rows (similar to boolean indexing in Pandas)
print(df.filter(pl.col('Age') > 30)) # Rows where Age is greater than 30
# > shape: (2, 3)
# > ┌─────────┬─────┬──────────┐
# > │ Name ┆ Age ┆ City │
# > ╞═════════╪═════╪══════════╡
# > │ Charlie ┆ 35 ┆ Paris │
# > │ David ┆ 40 ┆ New York │
# > └─────────┴─────┴──────────┘
print(df.filter((pl.col('Age') > 30) & (pl.col('City') == 'New York'))) # Multiple conditions
# > shape: (1, 3)
# > ┌───────┬─────┬──────────┐
# > │ Name ┆ Age ┆ City │
# > ╞═══════╪═════╪══════════╡
# > │ David ┆ 40 ┆ New York │
# > └───────┴─────┴──────────┘
print(df.filter(pl.col('City').is_in(['London', 'Paris']))) # Using is_in()
# > shape: (2, 3)
# > ┌─────────┬─────┬────────┐
# > │ Name ┆ Age ┆ City │
# > ╞═════════╪═════╪════════╡
# > │ Bob ┆ 30 ┆ London │
# > │ Charlie ┆ 35 ┆ Paris │
# > └─────────┴─────┴────────┘
Data Manipulation
Adding, modifying, or transforming data within a Polars DataFrame using expressions.
# Adding a new column (using .with_columns)
df_with_country = df.with_columns(pl.lit('USA').alias('Country')) # pl.lit creates a literal value
print(df_with_country)
# > shape: (4, 4)
# > ┌─────────┬─────┬──────────┬─────────┐
# > │ Name ┆ Age ┆ City ┆ Country │
# > ╞═════════╪═════╪══════════╪═════════╡
# > │ Alice ┆ 25 ┆ New York ┆ USA │
# > │ Bob ┆ 30 ┆ London ┆ USA │
# > │ Charlie ┆ 35 ┆ Paris ┆ USA │
# > │ David ┆ 40 ┆ New York ┆ USA │
# > └─────────┴─────┴──────────┴─────────┘
# Adding a new column based on existing ones (using .when().then().otherwise() or np.where)
df_with_age_group = df.with_columns(
pl.when(pl.col('Age') >= 30)
.then(pl.lit('Adult'))
.otherwise(pl.lit('Young'))
.alias('Age_Group')
)
print(df_with_age_group)
# > shape: (4, 4)
# > ┌─────────┬─────┬──────────┬───────────┐
# > │ Name ┆ Age ┆ City ┆ Age_Group │
# > ╞═════════╪═════╪══════════╪═══════════╡
# > │ Alice ┆ 25 ┆ New York ┆ Young │
# > │ Bob ┆ 30 ┆ London ┆ Adult │
# > │ Charlie ┆ 35 ┆ Paris ┆ Adult │
# > │ David ┆ 40 ┆ New York ┆ Adult │
# > └─────────┴─────┴──────────┴───────────┘
# Renaming columns
df_renamed = df.rename({'Name': 'Full_Name', 'City': 'Location'})
print(df_renamed)
# > shape: (4, 3)
# > ┌───────────┬─────┬──────────┐
# > │ Full_Name ┆ Age ┆ Location │
# > ╞═══════════╪═════╪══════════╡
# > │ Alice ┆ 25 ┆ New York │
# > │ Bob ┆ 30 ┆ London │
# > │ Charlie ┆ 35 ┆ Paris │
# > │ David ┆ 40 ┆ New York │
# > └───────────┴─────┴──────────┘
# Dropping columns
df_no_age = df.drop('Age')
print(df_no_age)
# > shape: (4, 2)
# > ┌─────────┬──────────┐
# > │ Name ┆ City │
# > ╞═════════╪══════════╡
# > │ Alice ┆ New York │
# > │ Bob ┆ London │
# > │ Charlie ┆ Paris │
# > │ David ┆ New York │
# > └─────────┴─────┴──────────┘
# Handling Missing Data (nulls)
data_missing = {'A': [1, 2, None], 'B': [4, None, 6]} # Use None for nulls in Polars
df_missing = pl.DataFrame(data_missing)
print(df_missing)
# > shape: (3, 2)
# > ┌───────┬───────┐
# > │ A ┆ B │
# > ╞═══════╪═══════╡
# > │ 1 ┆ 4 │
# > │ 2 ┆ null │
# > │ null ┆ 6 │
# > └───────┴───────┘
print(df_missing.drop_nulls()) # Drops rows with any null values
# > shape: (1, 2)
# > ┌───────┬───────┐
# > │ A ┆ B │
# > ╞═══════╪═══════╡
# > │ 1 ┆ 4 │
# > └───────┴───────┘
print(df_missing.fill_null(0)) # Fills null values with 0
# > shape: (3, 2)
# > ┌───────┬───────┐
# > │ A ┆ B │
# > ╞═══════╪═══════╡
# > │ 1 ┆ 4 │
# > │ 2 ┆ 0 │
# > │ 0 ┆ 6 │
# > └───────┴───────┘
print(df_missing.with_columns(
pl.col('A').fill_null(pl.col('A').mean()) # Fill with column mean
))
# > shape: (3, 2)
# > ┌───────────┬───────┐
# > │ A ┆ B │
# > ╞═══════════╪═══════╡
# > │ 1.0 ┆ 4 │
# > │ 2.0 ┆ null │
# > │ 1.5 ┆ 6 │
# > └───────────┴───────┘
Aggregation and Grouping
Summarizing data and performing operations on groups using Polars’ efficient group_by.
# Create a new DataFrame for aggregation examples
agg_data = {
'Category': ['A', 'B', 'A', 'B', 'A'],
'Value': [10, 20, 15, 25, 12],
'Count': [1, 1, 2, 1, 3]
}
df_agg = pl.DataFrame(agg_data)
print(df_agg)
# > shape: (5, 3)
# > ┌──────────┬───────┬───────┐
# > │ Category ┆ Value ┆ Count │
# > ╞══════════╪═══════╪═══════╡
# > │ A ┆ 10 ┆ 1 │
# > │ B ┆ 20 ┆ 1 │
# > │ A ┆ 15 ┆ 2 │
# > │ B ┆ 25 ┆ 1 │
# > │ A ┆ 12 ┆ 3 │
# > └──────────┴───────┴───────┘
# Basic aggregations
print(df_agg.select(pl.col('Value').sum())) # Sum of a column
# > shape: (1, 1)
# > ┌───────┐
# > │ Value │
# > ╞═══════╡
# > │ 82 │
# > └───────┘
print(df_agg.select(pl.col('Value').mean())) # Mean of a column
# > shape: (1, 1)
# > ┌──────────┐
# > │ Value │
# > ╞══════════╡
# > │ 16.4 │
# > └──────────┘
# Grouping data (group_by)
print(df_agg.group_by('Category').agg(
pl.col('Value').sum().alias('Total_Value'),
pl.col('Value').mean().alias('Average_Value'),
pl.col('Count').max().alias('Max_Count')
))
# > shape: (2, 4)
# > ┌──────────┬───────────┬───────────────┬───────────┐
# > │ Category ┆ Total_Value ┆ Average_Value ┆ Max_Count │
# > ╞══════════╪═══════════╪═══════════════╪═══════════╡
# > │ A ┆ 37 ┆ 12.333333 ┆ 3 │
# > │ B ┆ 45 ┆ 22.5 ┆ 1 │
# > └──────────┴───────────┴───────────────┴───────────┘
Combining DataFrames
Merging, joining, and concatenating DataFrames in Polars.
# Create two DataFrames for combining examples
df1 = pl.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': [1, 2, 3, 4]})
df2 = pl.DataFrame({'key': ['B', 'D', 'E', 'F'], 'value_2': [5, 6, 7, 8]})
df3 = pl.DataFrame({'A': [1, 2], 'B': [3, 4]})
df4 = pl.DataFrame({'A': [5, 6], 'B': [7, 8]})
# Concatenation (stacking DataFrames)
print(pl.concat([df3, df4])) # Concatenates rows by default (how='vertical')
# > shape: (4, 2)
# > ┌───┬───┐
# > │ A ┆ B │
# > ╞═══╪═══╡
# > │ 1 ┆ 3 │
# > │ 2 ┆ 4 │
# > │ 5 ┆ 7 │
# > │ 6 ┆ 8 │
# > └───┴───┘
print(pl.concat([df3, df4], how='horizontal')) # Concatenates columns
# > shape: (2, 4)
# > ┌───┬───┬───┬───┐
# > │ A ┆ B ┆ A ┆ B │
# > ╞═══╪═══╪═══╪═══╡
# > │ 1 ┆ 3 ┆ 5 ┆ 7 │
# > │ 2 ┆ 4 ┆ 6 ┆ 8 │
# > └───┴───┴───┴───┘
# Joins (merging)
print(df1.join(df2, on='key', how='inner')) # Only common keys
# > shape: (2, 3)
# > ┌─────┬───────┬─────────┐
# > │ key ┆ value ┆ value_2 │
# > ╞═════╪═══════╪═════════╡
# > │ B ┆ 2 ┆ 5 │
# > │ D ┆ 4 ┆ 6 │
# > └─────┴───────┴─────────┘
print(df1.join(df2, on='key', how='left')) # All keys from left, matching from right
# > shape: (4, 3)
# > ┌─────┬───────┬─────────┐
# > │ key ┆ value ┆ value_2 │
# > ╞═════╪═══════╪═════════╡
# > │ A ┆ 1 ┆ null │
# > │ B ┆ 2 ┆ 5 │
# > │ C ┆ 3 ┆ null │
# > │ D ┆ 4 ┆ 6 │
# > └─────┴───────┴─────────┘
print(df1.join(df2, on='key', how='right')) # All keys from right, matching from left
# > shape: (4, 3)
# > ┌─────┬───────┬─────────┐
# > │ key ┆ value ┆ value_2 │
# > ╞═════╪═══════╪═════════╡
# > │ B ┆ 2 ┆ 5 │
# > │ D ┆ 4 ┆ 6 │
# > │ E ┆ null ┆ 7 │
# > │ F ┆ null ┆ 8 │
# > └─────┴───────┴─────────┘
print(df1.join(df2, on='key', how='outer')) # All keys from both
# > shape: (6, 3)
# > ┌─────┬───────┬─────────┐
# > │ key ┆ value ┆ value_2 │
# > ╞═════╪═══════╪═════════╡
# > │ A ┆ 1 ┆ null │
# > │ B ┆ 2 ┆ 5 │
# > │ C ┆ 3 ┆ null │
# > │ D ┆ 4 ┆ 6 │
# > │ E ┆ null ┆ 7 │
# > │ F ┆ null ┆ 8 │
# > └─────┴───────┴─────────┘
Input/Output
Reading data from and writing data to various file formats.
# Create a dummy DataFrame to save
data_to_save = {'Col1': [10, 20, 30], 'Col2': ['A', 'B', 'C']}
df_io = pl.DataFrame(data_to_save)
# Saving to CSV
# df_io.write_csv('my_polars_data.csv')
# Reading from CSV
# df_read_csv = pl.read_csv('my_polars_data.csv')
# print(df_read_csv)
# # > shape: (3, 2)
# # > ┌──────┬──────┐
# # > │ Col1 ┆ Col2 │
# # > ╞══════╪══════╡
# # > │ 10 ┆ A │
# # > │ 20 ┆ B │
# # > │ 30 ┆ C │
# # > └──────┴──────┘
# Saving to Parquet
# df_io.write_parquet('my_polars_data.parquet')
# Reading from Parquet
# df_read_parquet = pl.read_parquet('my_polars_data.parquet')
# print(df_read_parquet)
# # > shape: (3, 2)
# # > ┌──────┬──────┐
# # > │ Col1 ┆ Col2 │
# # > ╞══════╪══════╡
# # > │ 10 ┆ A │
# # > │ 20 ┆ B │
# # > │ 30 ┆ C │
# # > └──────┴──────┘
# Saving to JSON
# df_io.write_json('my_polars_data.json')
# Reading from JSON
# df_read_json = pl.read_json('my_polars_data.json')
# print(df_read_json)
# # > shape: (3, 2)
# # > ┌──────┬──────┐
# # > │ Col1 ┆ Col2 │
# # > ╞══════╪══════╡
# # > │ 10 ┆ A │
# # > │ 20 ┆ B │
# # > │ 30 ┆ C │
# # > └──────┴──────┘
Polars’ syntax often relies on “expressions” (like pl.col('Age') > 30) which can be chained together, making operations very efficient.





