


What is pandas?
pandas is an open-source library built on top of NumPy. It provides us with new data structures (such as Series and DataFrames) and is designed to make it easy for us to work with tabular data.
A pandas Series is a 1-dimensional data structure similar to a Python list or a 1D NumPy array; the main difference is it is labeled. A DataFrame, on the other hand, is a 2-dimensional labeled data structure.
Importing the pandas Library
To use the pandas library, we need to import it. First, create a new notebook in Google Colab and name it pandas.ipynb.
Next, add the following code to the first cell and run it:
import pandas as pd
Similar to using np for NumPy, it is customary to use pd as the alias for pandas.
Creating a pandas Series
To create a pandas Series, we use the Series() constructor in the pandas library. We can pass array-like structures like Python lists, Python dictionaries, and NumPy arrays to the constructor. Let’s look at some examples:
list1 = [1, 2, 3, 4, 5]
print(list1, end='\n\n')
series1 = pd.Series(list1)
print(series1, end='\n\n')
series2 = pd.Series(list1, index=['P', 'Q', 'R', 'S', 'T'])
print(series2, end='\n\n')
If you run the code above, you’ll get the following output:
[1, 2, 3, 4, 5]
0 1
1 2
2 3
3 4
4 5
dtype: int64
P 1
Q 2
R 3
S 4
T 5
dtype: int64In the example above, we first create a list called list1. When we print this list, we get [1, 2, 3, 4, 5] as the output.
Next, we pass list1 to the Series() constructor to create a Series and assign the result to a variable called series1. When we print the value of series1, we get two columns of values. The column on the left is known as the index of the Series.
The individual values in the index are known as labels. For example, the label for the first element in series1 is 0, the second is 1, and so on.
After printing series1, we pass list1 to the Series() constructor again to create another Series. The default index of a Series is a running sequence of numbers. We can change that using the index parameter.
When creating series2, we pass index=[‘P’, ‘Q’, ‘R’, ‘S’, ‘T’] to the Series() constructor. As a result, the first element in series2 has a label of ‘P’, the second has a label of ‘Q’, and so on.
Creating a pandas DataFrame
Next, let’s learn to create a DataFrame. A DataFrame is very similar to a Series, except that it is two-dimensional.
To create a DataFrame, we use the DataFrame() constructor. Similar to the Series() constructor, we can pass array-like structures like Python lists, Python dictionaries, and NumPy arrays to this constructor. Let’s look at some examples:
# Creating from a 2D list
myList = [[1, 2, 3], [4, 5, 6]]
df1 = pd.DataFrame(myList)
print(df1, end='\n\n')
# Creating from a dictionary of lists
myDict = {'A':[1, 2, 3], 'B':[4, 5, 6]}
df2 = pd.DataFrame(myDict)
print(df2, end='\n\n')
Here, we create df1 using a 2D list (myList) and df2 using a dictionary of lists (myDict).
When we use a 2D list to create a DataFrame, the nested lists in the list form the rows of the DataFrame. In contrast, when we use a dictionary of lists, the lists in the dictionary form the columns.
If you run the code above, you’ll get the following output:
0 1 2
0 1 2 3
1 4 5 6
A B
0 1 4
1 2 5
2 3 6As you can see, a DataFrame is a two-dimensional data structure that comes with row and column labels. For instance, the columns in the last DataFrame above are labeled A and B, while the rows are labeled 0, 1, and 2.
We can specify the labels of a DataFrame when creating it. To do that, we use the index (for row labels) and columns (for column labels) parameters:
myList2 = [[1, 2, 3, 4, 5], [10, 20, 30, 40, 50]]
df3 = pd.DataFrame(myList2, index = ['A', 'B'], columns = ['1st', '2nd', '3rd', '4th', '5th'])
df3
Here, we specify the row labels of df3 as [‘A’, ‘B’] and the column labels as [‘1st’, ‘2nd’, ‘3rd’, ‘4th’, ‘5th’].
If you run the code above, you’ll get the following output:
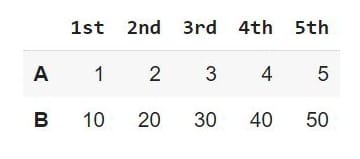
Notice that this DataFrame looks different from the previous DataFrames? This is because the last statement in the code snippet above is df3 instead of print(df3).
When the last statement in a Jupyter Notebook cell is a variable name, we do not need to use the print() function to print the variable; Jupyter Notebook does it for us automatically when we run the cell. If the variable is a DataFrame, Jupyter Notebook formats the DataFrame as a table before printing it.








